EXTENDED FRACTAL THEORY AND ITS APPLICATION IN CARTOGRAPHIC
GENERALIZATION
H. Wu
School of resource and environmental science, Wuhan
University, Wuhan 430079, China
hh_wu@x263.net
Generally speaking, a map or database to be designed may be consisted of only a subset of geo objects from the original map or database. Therefore first of all the determination of“which feature classes” and “how many”objects should be carried out. This is a map / database “conception”model. The “how many”problem can be considered as a problem about the total map load or database capacity.
In the case of traditional map compilation, the solution of this problem is realized empirically. In the digital environment, it is possible to solve the sub-problem (graphic element) automatically through program evaluation of digital map or spatial database.
Because fractal theory especially the extended fractal approach can derive the relationship between the observation measures and the observed results, the derived relationship can be used to determine the“full view”of new map or new database(fig. 1).
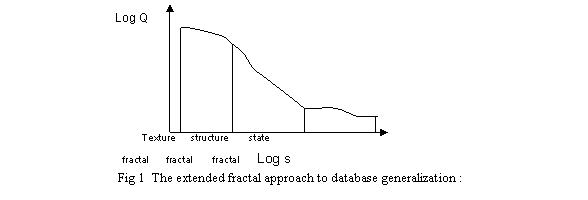
Because the difficulty in description of geo-features using a single value of fractal dimension, it is necessary to perform extension from the original constant dimension value which is independent upon measure step lengths to variable one which can be considered as a function depended upon measure step lengths. In this paper the author proposed principles and methods to establish the inverse S shaped curve function ( sigmoid ) and to examine the suitability of this model for enhancing the ability to describe complexed phenomena.
Here S is the measures of observation, Q is the observed results.
Using the
fractal method mentioned above we can determine approximately the required
capacity Qi of a new map to be designed if the map measure Si (scale ) is
given. Such a approach possesses an adaptive property, i. e. the required
parameters are derived from map or database itself. Here we use the symbols Qo
and Qi to represent the map loads of the source map and the current one
respectively and we can obtain the coefficient of map load reduction:
Ki=Qi/Qo
The
evaluated total map load Qi should be distributed according to the given
feature classes with the following automated distribution approach proposed by
the author .
So far we already obtained map load for each feature class. The next step is to create structured model determining which or what objects should be selected according to the distributed map load for each feature class(fig.2).
Fig.2 Distribution Of The New Map Load For Each Feature Class
In order to improve the application of fractal theory in map generalization first of all the line feature object (contour line ) should be automatically divided into several segments by its local curvature.
After curve segmentation the fractal method generalization will be carried out for each curve segment individually. The main procedures are as follows:
Using the fractal geometry a very essential parameter – fractal dimension value of an object itself or of object set – can be obtained. This parameter describes variation rate with the change of scale of observations in preserving self – similarity. Because fractal dimension value describes structure aspects both for individual object and for object set, therefore it can be used in structured generalization.
For point, line and area feature generalization, the fractal dimension value can be estimated by coarsening the view units, e.g. increasing the grid size to count the non-empty cells. Because fractal theory especially the extended fractal approach can automatically provide an adaptive solution, based on this theory a more structured generalization principle can be established.
Here a new method of improved Toepfer's radical selection law is used in which a relationship between curve length and map scale can be established:
L2=L1(M1/M2)D.
here L1, L2 the curve lengths before and after generalization respectively; M1, M2 the denominators of map scales before and after generalization. L2 can be seen as a kind of regressive expectation value by which the desirable offset distance d for line simplification can be determined:
![]()
Namely, if d2 will be accepted as offset distance for generalization, then after generalization the new line will have length L2 approximately.